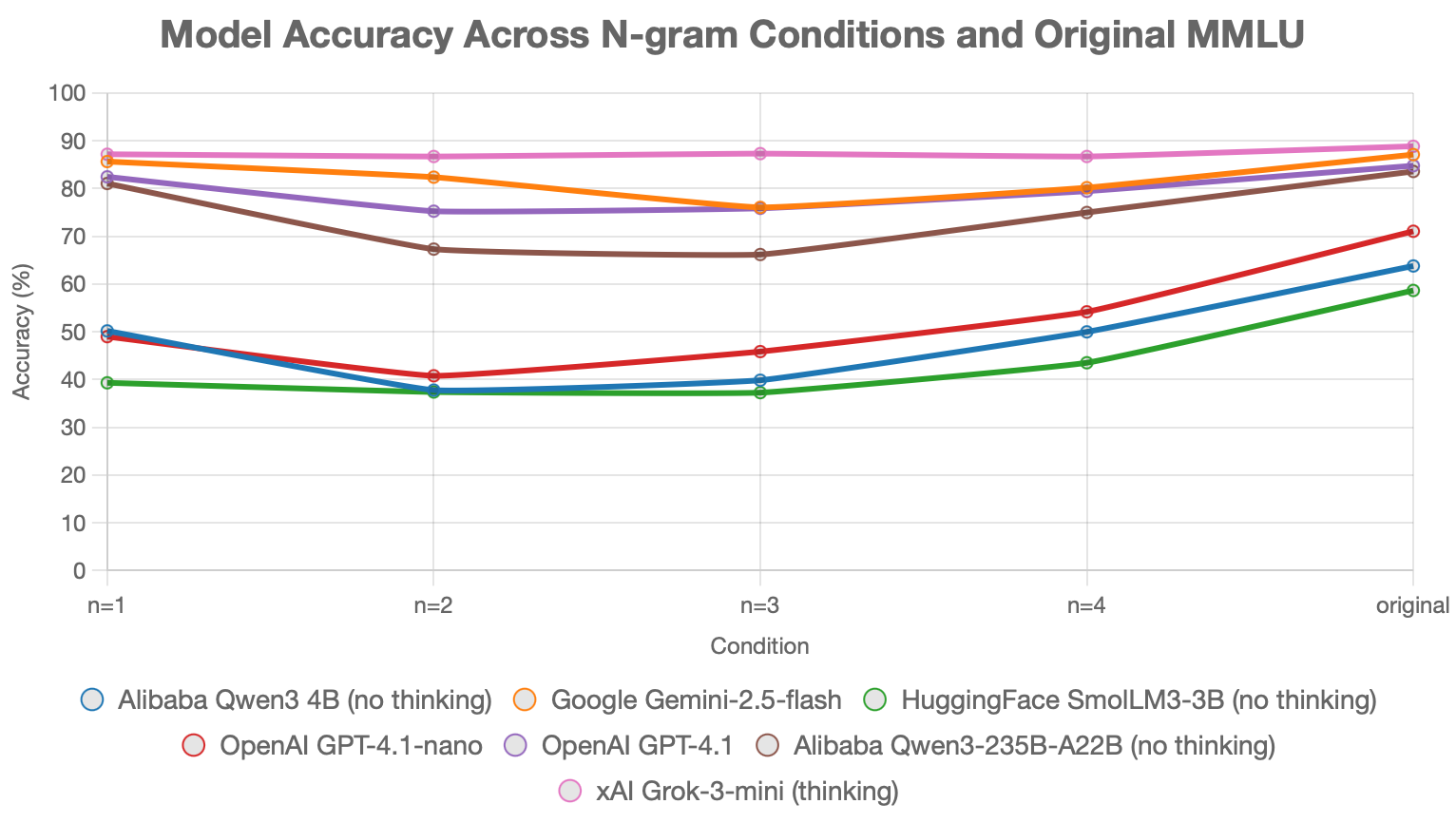
MMLU-NGRAM
My Age: 17
MMLU-NGRAM is a robustness benchmark I built and published on Hugging Face. It takes the full 14,042-question MMLU test set and rewrites each question into character n-grams of sizes 1 through 4 — separated by spaces, with words shorter than n left intact. The goal is to evaluate LLM performance on unconventional, hard-to-read inputs. Benchmarks were run on a random 1,500-sample subset across Grok-3-mini, GPT-4.1, GPT-4.1-nano, Gemini 2.5 Flash, Qwen3-4B, Qwen3-235B-A22B, and SmolLM3-3B. Grok-3-mini (thinking) led with 87%+ across every n; most other models dropped 20–30 accuracy points from the original baseline, revealing brittleness in tokenization and reading robustness.